O que é o Step?
Este step atua como um conversor universal de documentos, traduzindo diferentes formatos em texto estruturado. Na prática, ele:- Lê arquivos como PDF, Word, apresentações e imagens
- Interpreta estrutura (títulos, listas, tabelas, etc.)
- Converte tudo para Markdown
- Entrega um conteúdo organizado e pronto para uso em IA
Diferente de outros steps:
- Não gera apenas texto bruto
- Preserva estrutura lógica do documento
Onde encontrar
- Acesse o AI Studio
- Clique em Add AI Step
- Selecione Document Processing
- Escolha Marker Document Processing
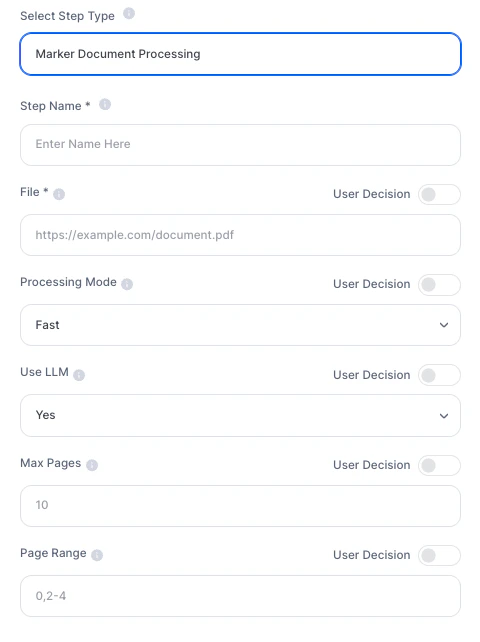
Como usar?
Campos de configuração
Explicação mais profunda
Esse step funciona como um tradutor de documentos para linguagem estruturada (Markdown).Fluxo
Documento (PDF, DOCX, imagem…) → Step interpreta estrutura↓Converte para Markdown → Agente recebe conteúdo organizado
Markdown vs Texto puro
Comparação prática:- Extract Text (DOCX, TXT, etc.) → texto linear bruto
- Marker Document Processing → texto estruturado (com hierarquia)
# Título
## Subtítulo
- Item 1
- Item 2
| Coluna A | Coluna B |
|----------|----------|
Exemplos práticos
Centralização de materiais de marketing
Centralização de materiais de marketing
- PDFs, apresentações e e-books
- Converter tudo para Markdown
- Usar como base para geração de conteúdo
Extração de propostas comerciais
Extração de propostas comerciais
- Processar contratos ou propostas
- Ativar Use LLM para melhor leitura de tabelas
- Extrair:
- valores
- prazos
- cláusulas
Triagem de currículos (multiformato)
Triagem de currículos (multiformato)
- PDFs, imagens, DOCX
- Padronizar tudo em Markdown
- Agente compara com vaga automaticamente
Criação de base de conhecimento
Criação de base de conhecimento
- Documentos internos → Markdown
- Alimentar agentes de suporte ou FAQ
Extração de dados tabulares
Extração de dados tabulares
Prompt:
“Extraia todas as tabelas e organize os dados em formato estruturado.”
“Extraia todas as tabelas e organize os dados em formato estruturado.”
Observações importantes
- Links com login ou preview não funcionam
- Use LLM aumenta tempo e custo
- Arquivos grandes impactam performance
- Estrutura é preservada, mas não perfeita em todos os casos