O que é o Step?
Este step faz parte da categoria Document Processing, sendo responsável por limpar e simplificar dados provenientes de diferentes formatos. Na prática, ele:- Lê arquivos TXT, XML, RSS e JSON
- Remove:
- tags XML
- estruturas JSON (chaves, arrays)
- metadados de RSS
- Mantém apenas o conteúdo semântico relevante
- Entrega um bloco de texto limpo no contexto do agente
Onde encontrar
- Acesse o AI Studio
- Clique em Add AI Step
- Selecione Document Processing
- Escolha Extract Text from TXT, XML, RSS, and JSON
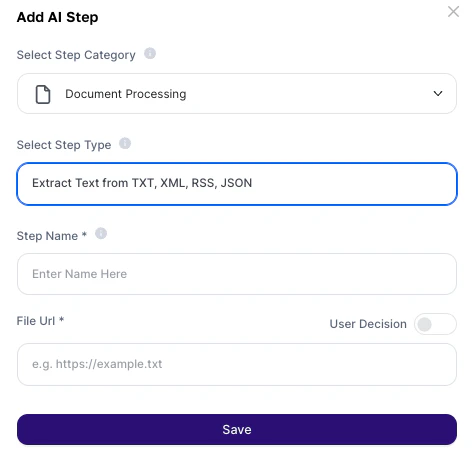
Como usar?
Campos de configuração
Sobre o Output
O resultado é um bloco contínuo de texto puro, sem qualquer estrutura técnica original.O que é mantido:
- Conteúdo semântico (nomes, descrições, valores)
- Todo o texto que é relevante para leitura humana
O que é removido:
- Tags XML (
<tag>) - Estruturas JSON (
{},[]) - Metadados de RSS
- Sintaxe técnica
Explicação mais profunda
Esse step atua como um normalizador de dados técnicos para linguagem natural.Fluxo
Arquivo (TXT / XML / RSS / JSON) → Step remove estrutura técnica↓Texto limpo é gerado → Agente interpreta semanticamente
Atenção:
- A IA passa a focar no conteúdo, não na estrutura
- Ideal para inputs que originalmente não foram feitos para leitura humana
Exemplos práticos
Monitoramento automatizado de notícias (RSS)
Monitoramento automatizado de notícias (RSS)
Prompt:
“Resuma as principais notícias do dia e identifique tendências relevantes para o mercado.”Uso:
“Resuma as principais notícias do dia e identifique tendências relevantes para o mercado.”Uso:
- Feed RSS de portais
- Agente gera curadoria automática
Análise de logs de atendimento (TXT)
Análise de logs de atendimento (TXT)
Prompt:
“Analise os logs e identifique os principais motivos de contato e sentimento dos clientes.”Uso:
“Analise os logs e identifique os principais motivos de contato e sentimento dos clientes.”Uso:
- Logs de chat ou suporte
- Classificação automática de problemas
Integração com CRM (JSON)
Integração com CRM (JSON)
Prompt:
“Com base nos dados extraídos, gere um e-mail de prospecção personalizado para cada lead.”Uso:
“Com base nos dados extraídos, gere um e-mail de prospecção personalizado para cada lead.”Uso:
- Export JSON de CRM
- IA transforma em ação comercial
Processamento de APIs e dados técnicos
Processamento de APIs e dados técnicos
Prompt:
“Organize as informações extraídas e destaque os principais indicadores.”Uso:
“Organize as informações extraídas e destaque os principais indicadores.”Uso:
- Respostas de APIs
- Transformar dados técnicos em insights
Observações importantes
- A URL deve ser pública e direta (sem login)
- Estrutura hierárquica original é perdida
- O step não mantém formatação nem organização de dados
- Arquivos grandes podem impactar contexto