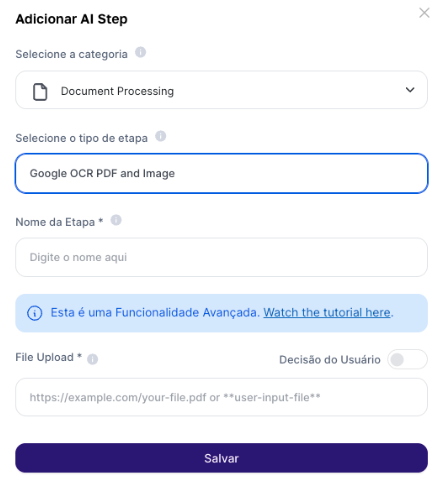
**Campos de Preenchimento: **Upload do arquivo PDF - Faça upload do PDF ou imagem que deseja extrair as informações. **Resultado de Output: **O texto extraído será apresentado em um formato digitado, com alta fidelidade ao conteúdo original.
Casos de Uso:
Digitalização de Documentos Arquivados
Converta grandes volumes de documentos arquivados em papel para formatos digitais, facilitando o acesso e a pesquisa de informações. Com auxílio da IA, você poderá preparar resumos e obter análises desses materiais.
Extração de Informações de Contratos
Utilize IA para extrair termos e condições de contratos armazenados em PDF, integrando-os a sistemas de gestão contratual e até criando metodologias de comparação e fraudes contratuais. Nesse caso, o conteúdo podem ser prints, por exemplo.
Processamento de Reclamações de Seguros
Companhias de seguros podem implementar a IA para OCR para digitalizar e processar rapidamente documentos de reclamações, acelerando o tempo de resposta e melhorando a satisfação do cliente.
Extração de textos de Imagens
Com esta etapa você pode extrair quaisquer informações e dados contidos em imagens e, com auxílio dos modelos de IA, poderá preparar resumos, estruturar insights e utilizar o texto extraído para qualquer análise necessária.
Limitações:
- A qualidade da conversão pode variar dependendo da qualidade do documento original e da complexidade do layout.
- O treinamento não pode ultrapassar o número de tokens do LLM selecionado. Isso pode variar entre 10.000 a 140.000 palavras. Portanto, certifique-se de que o PDF selecionado esteja dentro deste limite. Caso você tenha um PDF com mais que o limite, considere dividi-lo em partes menores.