O que é?
É a configuração que define o “tamanho da memória ativa” do modelo em cada execução. Na prática, quanto maior o contexto:- Mais histórico o modelo considera
- Maior o custo por execução
O Memory Economy Mode permite ajustar isso dinamicamente, priorizando economia ou profundidade.
Antes de usar: o que você precisa saber
Antes de alterar essa configuração, vale entender alguns pontos importantes:- É uma configuração por usuário: Cada usuário define sua própria preferência e a sua escolha não altera automaticamente a experiência de outros membros do workspace
- É uma configuração global da sua experiência na Tess: Ela não vale só para um único chat, o ajuste passa a influenciar suas conversas na plataforma de forma geral, nem se torna uma configuração “por prompt”.
- Você não precisa redefinir isso a cada nova conversa: Depois de ajustada, a preferência continua ativa até você mudar novamente, o objetivo principal é equilibrar qualidade e custo
Mais contexto melhora retenção do histórico. Menos contexto reduz gasto de tokens, especialmente em chats longos
Onde encontrar?
1
Acesse Preferências
No canto inferior esquerdo, clique em seu ícone de usuário e acesse a opção de configurações > preferências.
2
Encontre o Memory Economy Mode
Desça até a opção de configuração de economia de memória.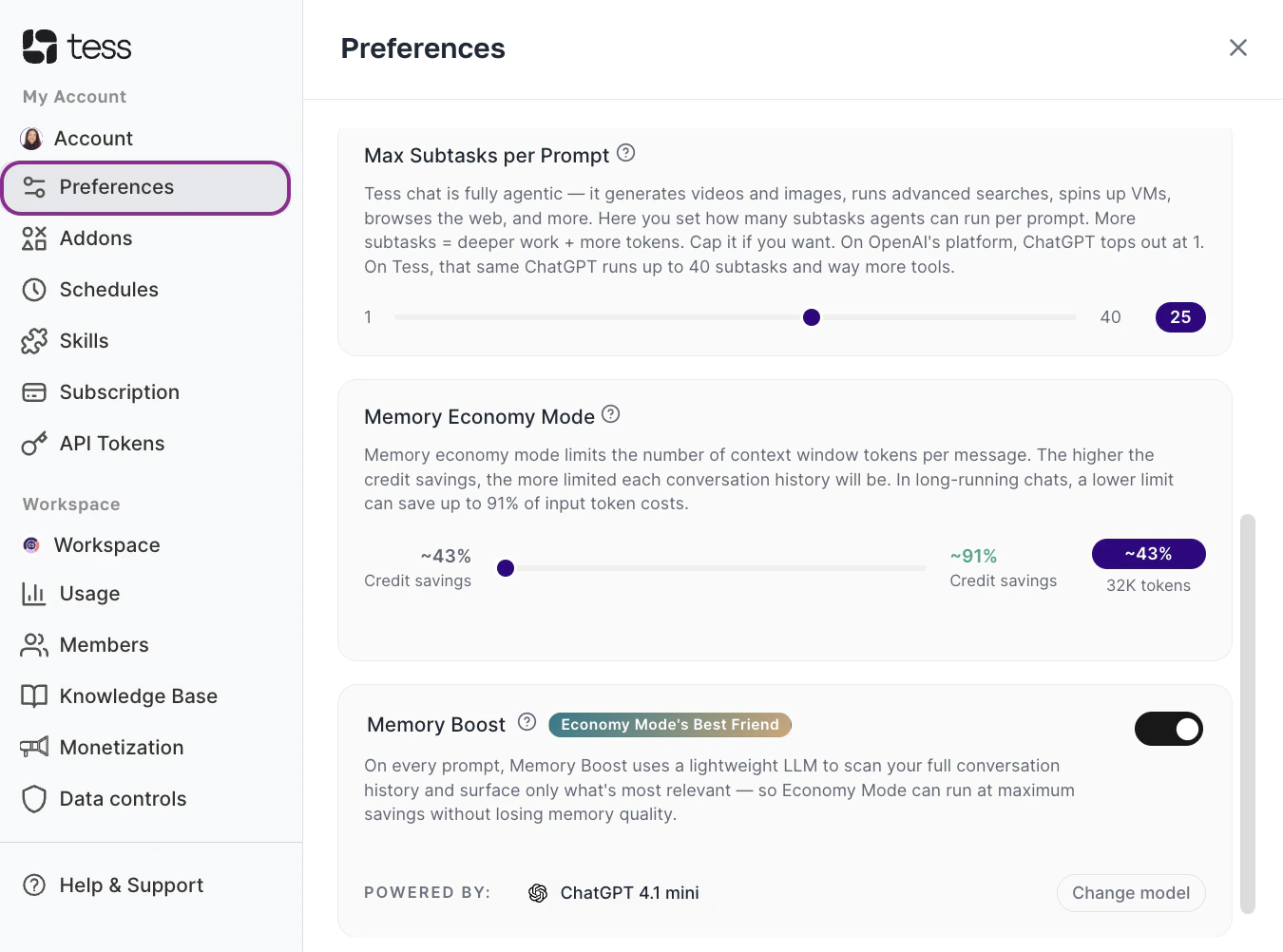
3
Ajuste o Slider
- Mais à direita → mais economia
- Mais à esquerda → mais contexto (ex: o padrão e a janela de 32K tokens)
4
Siga usando a Tess
Como interpretar o Memory Economy Mode
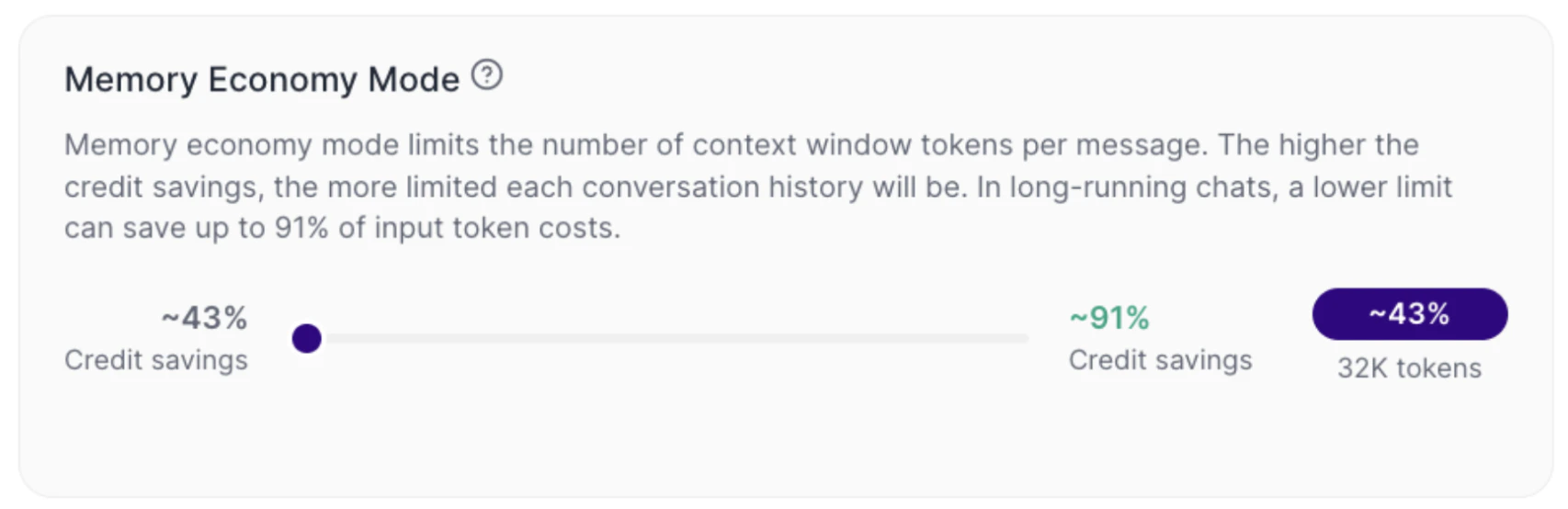
O Memory Economy Mode funciona como um controle entre economia e profundidade de contexto.Quando o slider está mais voltado para economia (direita)
A Tess limita mais fortemente a quantidade de tokens por mensagem. Na prática, o custo tende a cair, o histórico útil que o LLM vai usar da conversa fica menor, chats longos podem perder continuidade mais cedo. A configuração padrão é de 32K tokems, 43% credit saving. 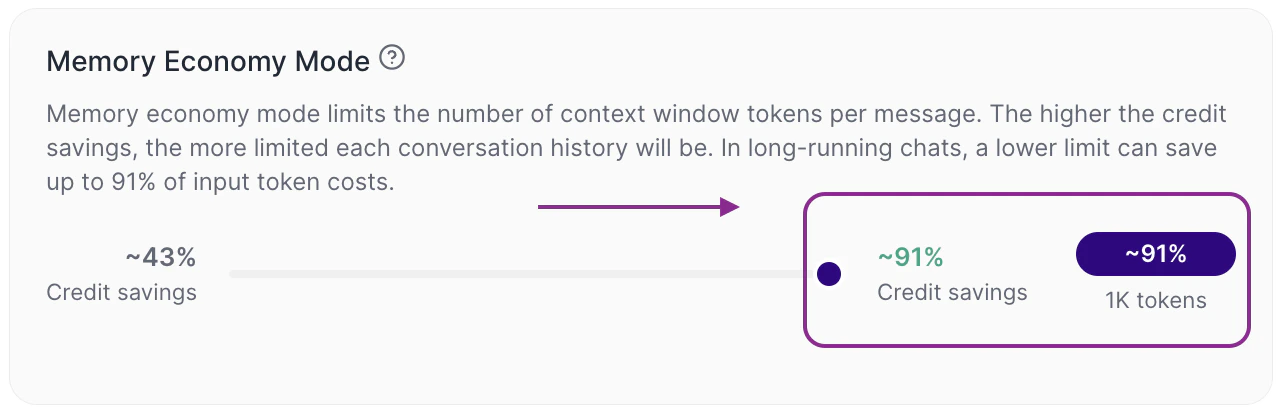
Quando o slider está mais voltado para contexto (esquerda)
A Tess amplia o limite disponível por mensagem. Na prática, mais histórico pode ser considerado pelo LLM, a continuidade tende a melhorar e o custo por entrada (input token) tende a subir, afinal, é muito mais conteúdo sendo revisto pelo modelo de texto para compor sua memória. Na própria interface, você verá indicadores como: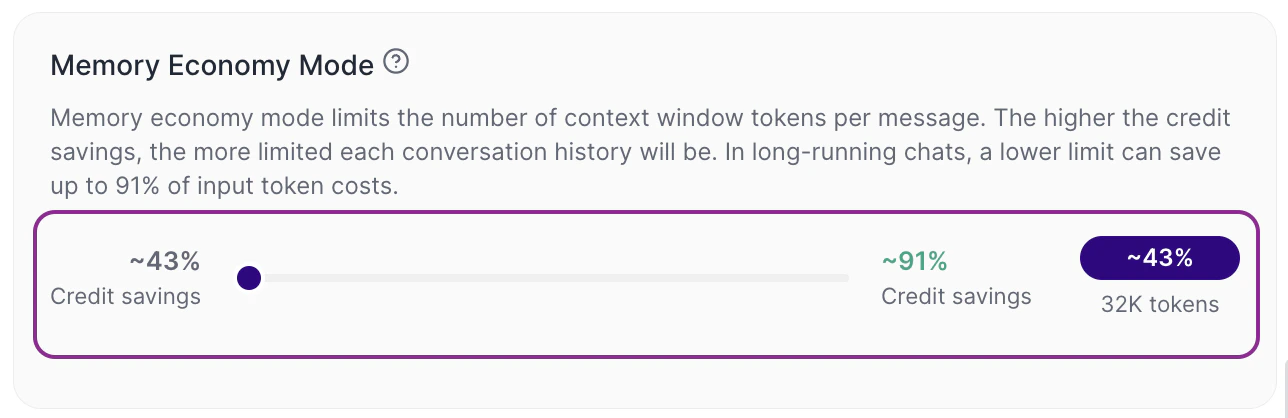
- percentual estimado de economia de créditos
- limite de contexto aproximado, como 32K tokens
Como isso funciona na prática
De modo geral, essa configuração é mais relevante em conversas longas. Em um chat curto, a diferença pode ser pequena. Já em um chat que acumula muito histórico, o limite de contexto passa a importar mais, porque o modelo não consegue considerar tudo indefinidamente. Isso significa que, em conversas extensas:- com contexto menor, partes antigas podem deixar de ser consideradas
- com contexto maior, a continuidade tende a ser melhor
- com Memory Boost ativo, a Tess pode recuperar trechos relevantes do histórico mesmo mantendo um limite mais econômico
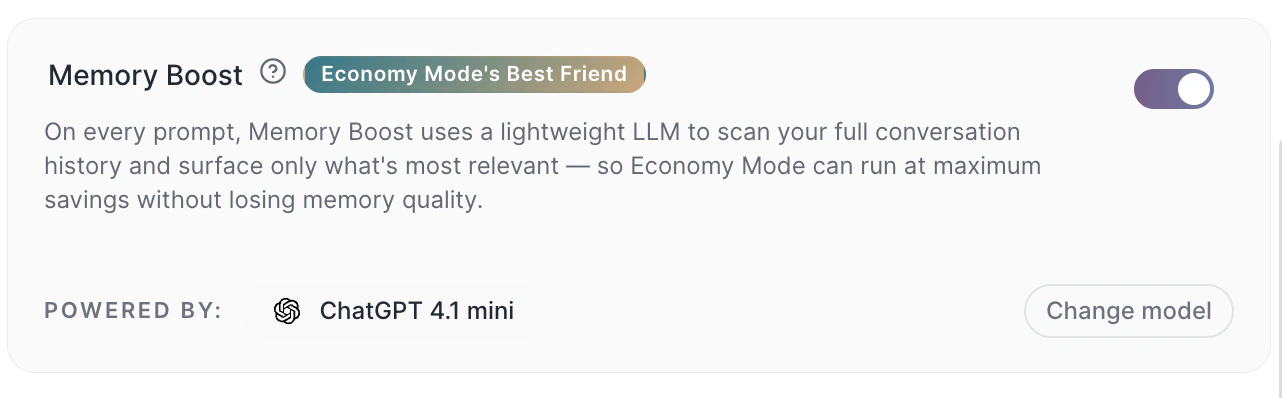
A janela de contexto não é apenas uma configuração técnica. Ela muda o comportamento real da IA ao longo do uso.
Isso significa que a plataforma controla quanto histórico será efetivamente enviado para o modelo a cada nova interação.
Por isso, o ajuste do Memory Economy Mode funciona como uma política individual de uso: você decide priorizar mais economia ou priorizar mais retenção de histórico. Esse controle é especialmente útil para quem quer escalar o uso da Tess com mais previsibilidade de custo.Além disso, o limite definido impacta todas as mensagens do chat e modelos que forem usados para conversar. Entretanto, ao ativar o modo Max, o modelo ignora essa configuração e usa o limite máximo nativo de cada modelo.
Exemplos práticos de contexto e configurações
Exemplo 1: uso rápido e operacional Se você usa a Tess para tarefas como revisar textos curtos, responder dúvidas objetivas ou gerar pequenas variações de conteúdo, por exemplo, um modo mais econômico costuma ser suficiente.Exemplo de prompt:Exemplo 2: conversa estratégica e contínua Se você está usando a Tess para construir um plano ao longo de várias interações amadurecer uma análise ou trabalhar em um projeto com contexto acumulado, um contexto maior tende a funcionar melhor.
“Reescreva esse parágrafo em um tom mais profissional.” Nesse caso, não há necessidade de manter muito histórico da conversa.
Exemplo de prompt:Observações importantes
“Considere tudo o que discutimos até aqui e organize uma proposta final em tópicos.” Aqui, a continuidade faz diferença no resultado, pode ser importante rever seu limite máximo.
- Mais contexto = maior consumo de créditos
- Menos contexto pode fazer a IA “esquecer” partes da conversa
- O impacto é maior em chats longos
- O valor exibido (ex: 32K tokens) é um limite aproximado
Erros comuns
- Deixar contexto alto para tudo: Isso aumenta o custo mesmo em tarefas simples que não precisam de longo histórico.
- Deixar contexto muito baixo em chats estratégicos: Isso pode prejudicar a continuidade e gerar respostas menos consistentes ao longo da conversa.
- Tratar essa configuração como algo por chat: O ajuste é feito nas preferências do usuário e influencia a experiência de forma ampla na plataforma.
- Ignorar o impacto em créditos: Quanto mais contexto for usado por mensagem, maior tende a ser o custo de entrada em conversas longas.