¿Qué es el Step?
Este step actúa como un conversor universal de documentos, traduciendo diferentes formatos a texto estructurado. En la práctica:- Lee archivos como PDF, Word, presentaciones e imágenes
- Interpreta la estructura (títulos, listas, tablas, etc.)
- Convierte todo a Markdown
- Entrega contenido organizado y listo para uso en IA
A diferencia de otros steps:
- No genera solo texto bruto
- Preserva la estructura lógica del documento
Dónde encontrarlo
- Accede al AI Studio
- Haz clic en Add AI Step
- Selecciona Document Processing
- Elige Marker Document Processing
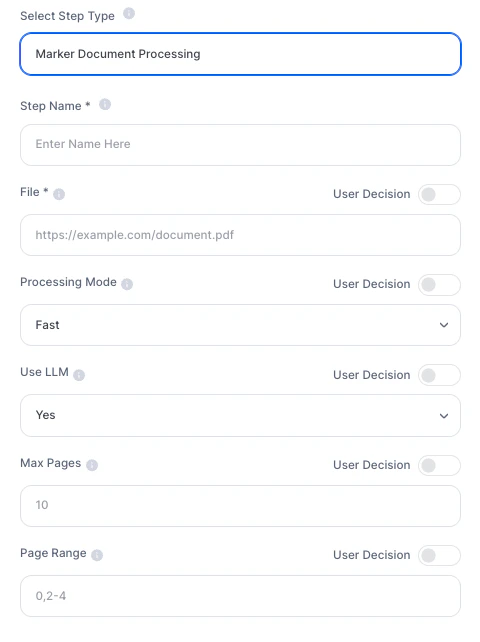
¿Cómo usar?
Campos de configuración
Explicación más profunda
Este step funciona como un traductor de documentos a lenguaje estructurado (Markdown).Flujo
Documento (PDF, DOCX, imagen…) → Step interpreta la estructura↓Convierte a Markdown → El agente recibe contenido organizado
Markdown vs texto plano
Comparación práctica:- Extract Text (DOCX, TXT, etc.) → texto lineal bruto
- Marker Document Processing → texto estructurado (con jerarquía)
# Título
## Subtítulo
- Item 1
- Item 2
| Columna A | Columna B |
|----------|----------|
Ejemplos prácticos
Centralización de materiales de marketing
Centralización de materiales de marketing
- PDFs, presentaciones y e-books
- Convertir todo a Markdown
- Usar como base para generación de contenido
Extracción de propuestas comerciales
Extracción de propuestas comerciales
- Procesar contratos o propuestas
- Activar Use LLM para mejor lectura de tablas
- Extraer:
- valores
- plazos
- cláusulas
Filtrado de currículums (multiformato)
Filtrado de currículums (multiformato)
- PDFs, imágenes, DOCX
- Estandarizar todo en Markdown
- El agente compara con la vacante automáticamente
Creación de base de conocimiento
Creación de base de conocimiento
- Documentos internos → Markdown
- Alimentar agentes de soporte o FAQ
Extracción de datos tabulares
Extracción de datos tabulares
Prompt:
“Extrae todas las tablas y organiza los datos en formato estructurado.”
“Extrae todas las tablas y organiza los datos en formato estructurado.”
Observaciones importantes
- Links con login o vista previa no funcionan
- Use LLM aumenta tiempo y costo
- Archivos grandes afectan el rendimiento
- La estructura se preserva, pero no es perfecta en todos los casos