¿Qué es el Step?
Este step forma parte de la categoría Document Processing, y es responsable de limpiar y simplificar datos provenientes de distintos formatos. En la práctica:- Lee archivos TXT, XML, RSS y JSON
- Elimina:
- etiquetas XML
- estructuras JSON (claves, arrays)
- metadatos de RSS
- Conserva solo el contenido semántico relevante
- Entrega un bloque de texto limpio en el contexto del agente
Dónde encontrarlo
- Accede al AI Studio
- Haz clic en Add AI Step
- Selecciona Document Processing
- Elige Extract Text from TXT, XML, RSS, and JSON
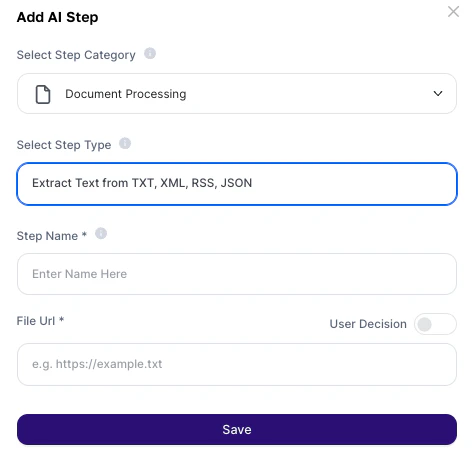
¿Cómo usar?
Campos de configuración
Sobre el Output
El resultado es un bloque continuo de texto plano, sin ninguna estructura técnica original.Qué se conserva:
- Contenido semántico (nombres, descripciones, valores)
- Todo el texto relevante para lectura humana
Qué se elimina:
- Etiquetas XML (
<tag>) - Estructuras JSON (
{},[]) - Metadatos de RSS
- Sintaxis técnica
Explicación más profunda
Este step actúa como un normalizador de datos técnicos a lenguaje natural.Flujo
Archivo (TXT / XML / RSS / JSON) → El step elimina la estructura técnica↓Se genera texto limpio → El agente interpreta semánticamente
Atención:
- La IA se enfoca en el contenido, no en la estructura
- Ideal para inputs que originalmente no fueron diseñados para lectura humana
Ejemplos prácticos
Monitoreo automatizado de noticias (RSS)
Monitoreo automatizado de noticias (RSS)
Prompt:
“Resume las principales noticias del día e identifica tendencias relevantes para el mercado.”Uso:
“Resume las principales noticias del día e identifica tendencias relevantes para el mercado.”Uso:
- Feed RSS de portales de noticias
- El agente genera curación automática
Análisis de logs de atención (TXT)
Análisis de logs de atención (TXT)
Prompt:
“Analiza los logs e identifica los principales motivos de contacto y el sentimiento de los clientes.”Uso:
“Analiza los logs e identifica los principales motivos de contacto y el sentimiento de los clientes.”Uso:
- Logs de chat o soporte
- Clasificación automática de problemas
Integración con CRM (JSON)
Integración con CRM (JSON)
Prompt:
“Con base en los datos extraídos, genera un correo de prospección personalizado para cada lead.”Uso:
“Con base en los datos extraídos, genera un correo de prospección personalizado para cada lead.”Uso:
- Export JSON de CRM
- La IA transforma los datos en acción comercial
Procesamiento de APIs y datos técnicos
Procesamiento de APIs y datos técnicos
Prompt:
“Organiza la información extraída y destaca los principales indicadores.”Uso:
“Organiza la información extraída y destaca los principales indicadores.”Uso:
- Respuestas de APIs
- Transformar datos técnicos en insights
Observaciones importantes
- La URL debe ser pública y directa (sin inicio de sesión)
- La estructura jerárquica original se pierde
- El step no conserva el formato ni la organización de los datos
- Los archivos grandes pueden afectar la ventana de contexto